プロを目指す人のためのRuby入門 言語仕様からテスト駆動開発・デバッグ技法まで
Overview
- この記事は「プロを目指す人のためのRuby入門 言語仕様からテスト駆動開発・デバッグ技法まで」という本を読み進める上での読書メモです。
- 気になったことやコマンドなどを時系列で整理しています。
- ほぼ全てのコードをこちらのサンプルコードより拝借しています
- メモ用のリポジトリ
実行環境
docker-compose.yml
version: '3'
services:
ruby:
build: .
tty: true
ports:
- "3001:3000"
volumes:
- .:/workDockerfile
FROM ruby:3.1.2
# 必要最低限のツールを入れる
RUN apt-get update -qq && apt-get install -y vim
# アプリケーションディレクトリを作成
RUN mkdir work
# アプリケーションディレクトリを作業用ディレクトリに設定
WORKDIR /work
ADD . .
EXPOSE 3000便利なコマンド
$ alias ruby='docker compose exec ruby'
$ ruby ruby sample.rbサンプルスクリプト
Capter02 rubyの基礎を理解する。
irbの起動
irbシェバンでrubyを実行すると何が良い?
rubyの公式リファレンス
- https://docs.ruby-lang.org/ja/
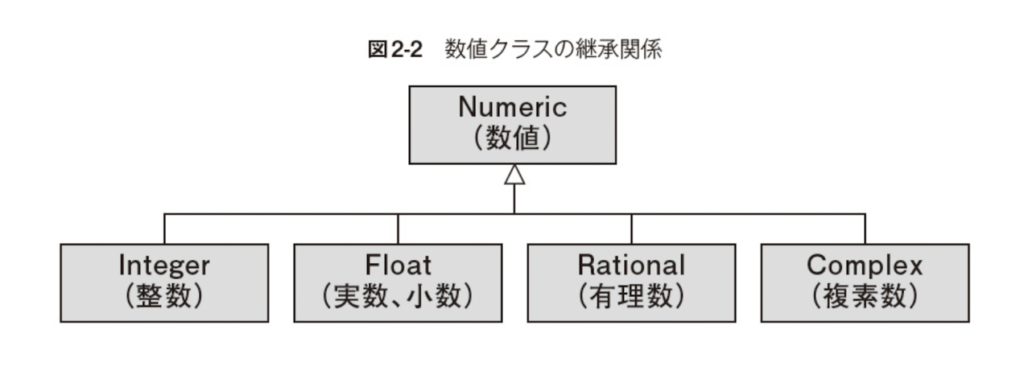
Rationalクラスと丸誤差とは?
rubyのクラス継承コードはどこで見れるんだろう?
orの面白い使い方
country or return 'countryを入力してください'エンドレスメソッド定義
def hello
puts 'hello'
enddef hello puts 'hello'標準ライブラリと組み込みライブラリ
標準ライブラリgem化の流れ
標準ライブラリはどんどんgemとして切り離されているみたい。
そのほうが使い回しが効くので便利だからだろうね。
特にアップデートの時とかに重宝しそう。
require, require_relativeの違い
- require … 標準ライブラリやgemを使う場合(絶対パス)
- require_relative … 自作のライブラリを読み込む場合(相対パスで読み込める)
パスの通っていない自作のライブラリは、実行場所によってパスが変わるからrequireで読み込むのは推奨されていないみたい。
この章を終えて
文字列操作やifはプログラムの基本だけど言語によって方言のような特徴が出る。
rubyにはrubyの特徴があって、その小さな違いがバグを生んだりする。
ここで基本をさらっと学んでおくことには後々意味があるんだよね。
今は全部覚えなくても、出てきた時に思い出せれば良い。
例えば、整数と小数は使えるメソッドが違うよね。
to_i
to_fCapter03 テストを自動化する。
require 'minitest/autorun'
require_relative '../lib/fizz_buzz'
class FizzBuzzTest < Minitest::Test
def test_fizz_buzz
assert_equal '1', fizz_buzz(1)
assert_equal '2', fizz_buzz(2)
assert_equal 'Fizz', fizz_buzz(3)
assert_equal '4', fizz_buzz(4)
assert_equal 'Buzz', fizz_buzz(5)
assert_equal 'Fizz', fizz_buzz(6)
assert_equal 'FizzBuzz', fizz_buzz(15)
end
endCapter04 配列の繰り返しや処理を理解する
「10進数」
「0~9」までの数字からなる数値。
「16進数」
0から9までの数字とAからFまでのアルファベットの組み合わせ。
コンピューターではよく使われる。
特にカラーコードなんかは16進数。
よく使いそうなコマンド
- each … 配列に対して逐次処理によく使われる(非破壊的)
- 一般的な繰り返しはこれ。
- map/collect … 配列自体に処理内容を反映させる(破壊的)
- 空配列に入れ直すみたいなことは避けられる。
- sun … 配列の合計値を出してくれる。
- そのままも使えるし、ブロックにもできる。
- 文字列に対してやると+で連結される。
- join … 文字列の連結に使われる。
- 連結の際にto_sが呼ばれるので型違いでも大丈夫。
- 連結時に区切り文字も設定できる。
- ブロックにできないので柔軟性はsumに劣る。
範囲メソッド
- `..` … 開始と終了を範囲に含めない(X< && >Y)
- `…` … 開始と終了を範囲に含める(X<= && >=Y)
文字列抜き出しなんかでよく使いそう。
a = 'abcde'
a[1..3]不等号より範囲オブジェクト?
場合によっては範囲オブジェクトの方が便利。
def liquid?
0 <= templature && templature <= 100
enddef liquid?
(0...100).include?(templature)
endhexメソッドのリファクタリング履歴
def to_hex(r=0, g=0, b=0)
'#' +
r.to_s(16).rjust(2, '0') +
g.to_s(16).rjust(2, '0') +
b.to_s(16).rjust(2, '0')
enddef to_hex(r=0, g=0, b=0)
hex = '#'
[r,g,b].each do |n|
hex += n.to_s(16).rjust(2, '0')
end
hex
enddef to_hex(r=0, g=0, b=0)
[r,g,b].sum('#') do |n|
n.to_s(16).rjust(2, '0')
end
end
def to_ints(hex) = hex.scan(/\w\w/).map(&:hex)
# エンドレス構文で1行に
# scanと正規表現でhexを2文字ずつ抽出
# mapで抽出した文字列にメソッドを適応して破壊的に配列を作成
# (&:メソッド)で引数なしのメソッドを1つだけ呼び出すmapは破壊的メソッドで返り値がある
def to_ints(hex)
r = hex[1..2]
g = hex[3..4]
b = hex[5..6]
[r,g,b].map do |s|
s.hex
end
end実用性の低そうな(&:メソッド)
以下の条件下で利用できるみたい。
- ブロックパラメーターが1つのみ。
- ブロックの中で呼び出すメソッドには引数がない。
- ブロックの中でブロックパラメーターに対してメソッドを1つだけ呼び出す。
慣れるまでは使いたくないなあ。。。
引数なしのメソッドなんて標準のメソッドくらいじゃないかな??
(今回でいうhexみたいな、クラスオブジェクトに対して使うクラスメソッド)
テスト駆動開発のライフサイクル
- テストコードを書く。
- テストが失敗することを確認する。
- まずはここが最初の課題
- テストファイルをどこに作る?
- テストメソッド名は何にする?
- どんなassertionを作る?
- ちゃんとrequireできてる?
- 1つのテストをパスさせるための仮実装を書く。
- ここまではスピード重視
- テストがパスすることを確認する。
- 別のテストパターンを書く。
- 三角測量なので重要
- テストが失敗することを確認する。
- 仮実装ではなく、ちゃんとしたロジックを書く。
- 最も難儀する場所だろうね。
- テクニックもここからで発揮する。
- 40%程度の技術で対応する。
- テストがパスすることを確認する。
- ロジックをリファクタリングする。
- これは、時間との兼ね合いだね。
- テストがパスすることを確認する。
Fake it
固定値を返すような仮実装のことをこう呼ぶらしい。
テストと実装がしっかり疎通(リンク)していることを素早く確認するために必要見たい。
そもそもここでミスってたら馬鹿らしい時間の使い方になっちゃう。
三角測量
テストパターンを複数用意することで、テストの有効性を視点を変えて検証できる。
実装が仮実装なのか本実装なのかを判断することに使える。
ちなみに、三角測量という名前は「1辺の長さとその両端にある2角がわかれば、その交点から三角形の残りの1点を確定できる」という測量の原理に由来しています。テスト駆動開発の場合、「2角」が「2つのテストパターン」で、「残りの1点」が「正しい仕様」に該当します。
伊藤 淳一. プロを目指す人のためのRuby入門[改訂2版] 言語仕様からテスト駆動開発・デバッグ技法まで Software Design plus (p.343). 株式会社技術評論社. Kindle 版.
配列の連結
- a.contact(b) .. 破壊的メソッド
- a + b … 非破壊的メソッド
配列の集合
予約システムの日付計算とかで使えそう。
特定の期間内に予約があるとか、とか。
以下はいずれも非破壊的メソッド。
- a | b … 和集合(重複削除)
- a – b … 差集合(両方に共通 ‘しない’ 差分を抽出)
- a & b … 積集合(重複を抽出)
配列を効率的に扱えるSetメソッドとは??
caseメソッドを検索で使う
これは便利なcaseの使い方。
これまでなら、inlucde?とかで条件分岐していただろうね。
jp = ['japan', '日本']
country = '日本'
case coubtry
when *jp
'こんにちは'
end
=> "こんにちは"可変調引数を区切り文字で連結
def greet(*names)
"#{names.join('と')}、こんにちは"
end
greet(['田中さん', '鈴木さん'])可変調引数はrest引数とも呼ばれるらしい。
可変調引数内部での配列の展開
a = [1, 2, 3]
[-1, 0, *a, 4, 5] #=> [-1, 0, 1, 2, 3, 4, 5]%記法で配列を作る
# []で文字列の配列を作成する
['apple', 'melon', 'orange'] #=> ["apple", "melon", "orange"]
# %wで文字列の配列を作成する(!で囲む場合)
%w!apple melon orange! #=> ["apple", "melon", "orange"]
# %wで文字列の配列を作成する(丸カッコで囲む場合)
%w(apple melon orange) #=> ["apple", "melon", "orange"]
# 空白文字(スペースや改行)が連続した場合もひとつの区切り文字と見なされる
%w(
apple
melon
orange
)
#=> ["apple", "melon", "orange"]式展開なんかをやりたい場合は大文字のWを使う。
arrayを使った配列初期値の注意点
array.newの第二引数でデフォルト値を設定できるけど、全て同じオブジェクトになる。
どれか1つに変更を加えるとそのほかも影響を受けるので注意。
freezeでイミュータブルにする
rubyでは大文字変数は定数として説明されるけど、そのままではミュータブルなグローバル変数として活動する。
そこで、freezeメソッドを使うと、変更不可のイミュータブルなオブジェクトにすることができる。
よく使いそう。
PERMIT_ID = ['0001', '0002', '1234']
PERMIT_ID.freeze
PERMIT_ID.reject! { |id| id == '1234' }
# => RuntimeError: can't modify frozen Array添字を使うにはwixh_index
each_with_indexが有名だけど、実はwith_indexメソッドっていうのが存在する。
with_indexを使えばmapやdeleteなどの繰り返し処理に添え字をつけられる。
ちなみに、with_index(1)とすればゼロオリジンを変更して1からのスタートに変更できる。
each.with_index(1)で1スタートの添え字を使ってeachを回せる。
文字列連結でよく使いそうなjoinメソッド
(しれっとメソッドチェーンを使う)
names = ['田中', '鈴木', '佐藤']
names.map { |name| "#{name}さん" }.join('と')
# 以下と同じ
names.map do name
"#{name}さん"
end.join('と')配列をもっとうまく使いこなすために
配列は、これまでのコードの中で幾度となく使ってきたし、難儀してきた。
繰り返し処理に対する長すぎるコーディングはいつもバグの温床だったから、コンパクトにかけるならそれに越したことはない。
配列をもっと上手に使いこなすために Rubyの配列(Arrayクラス)には数多くのメソッドが定義されています。自分でがんばってコードを書かなくても、最初から用意されているメソッド1つで実装が完了するケースもよくあります。配列の要素をあれこれいじくり回すようなコードが書きたくなったら、手を動かす前に公式リファレンスに一通り目を通して使えそうなメソッドがないか探してみてください。「こんなコードを書こうとしているのは世界で自分1人だけか?」を自問してみて、その答えがNOであれば、すでにArrayクラスのメソッドとして実装されているかもしれません(たとえば「eachメソッドでループを回しながら、添え字を一緒に取得したいと思うのは世界で自分だけか?」「いや、そんなはずはない」という感じです)。 配列のメソッドはArrayクラス自身に定義されているものと、Enumerableモジュールに定義されているものに大別されるので、両方の公式リファレンスに目を通すことが重要です。 ・https://docs.ruby-lang.org/ja/latest/class/Array.html ・https://docs.ruby-lang.org/ja/latest/class/Enumerable.html 使えそうなメソッドが見つかったら、irbを起動して簡単なサンプルコードを動かしてみましょう。実際に動かしてみることで、本当にそのメソッドが自分の用途に合っているのかどうかを確認できます。こうしたプロセスを繰り返せば、だんだんと配列の使い方に慣れ、短いコードで複雑な処理を実装できるようになるはずです。
伊藤 淳一. プロを目指す人のためのRuby入門[改訂2版] 言語仕様からテスト駆動開発・デバッグ技法まで Software Design plus (pp.394-395). 株式会社技術評論社. Kindle 版.
Rubyの公式ドキュメントが面白そう
https://docs.ruby-lang.org/ja/latest/doc/index.html
each以外にも使えそうなループメソッド
uptoメソッド,downtoメソッド
a = []
10.upto(14) { |n| a << n }
14.upto(10) { |n| a << n }a = []
1.step(10, 2) { |n| a << n }
=> 1,3,5,7,9
10.step(1, -2) { |n| a << n }
=> 1,3,5,7,9後置whileでスッキリ
a = []
while a.size < 5
a << 1
end
=> [1,1,1,1,1]while a.size < 5 do a << 1 enda << 1 while a.size < 5破壊的メソッドは再代入を不要にしてくれる
再代入を行なってミスを減らし、記述を減らしてくれる。
a = []
(1..4).each do |n| a << n*10 end(1..4).map { |n| n*10 }大域脱出のcatch throw
fruits = ['apple', 'melon', 'orange']
numbers = [1, 2, 3]
catch :done do
fruits.shuffle.each do |fruit|
numbers.shuffle.each do |n|
puts "#{fruit}, #{n}"
if fruit == 'orange' && n == 3
# すべての繰り返し処理を脱出する
throw :done
end
end
end
endreturnとbreakの違い
- return … ループを含むメソッド事態からの脱出
- break … 純粋なループからの脱出(上位のメソッドは含まない)
処理をスキップしてくれるnext
def calc_with_return
numbers = [1, 2, 3, 4, 5, 6]
target = nil
numbers.shuffle.each do |n|
target = n
# returnで脱出する?
return if n.even?
end
target * 10
end
calc_with_return #=> nilredoで処理を巻き戻す
ユースケースとしては、、、クイズの点数とかかな???
if文を1つ省略できるところがイケてる。
foods = ['ピーマン', 'トマト', 'セロリ']
foods.each do |food|
print "#{food}は好きですか? => "
# sampleは配列からランダムに1要素を取得するメソッド
answer = ['はい', 'いいえ'].sample
puts answer
# はいと答えなければもう一度聞き直す
redo unless answer == 'はい'
end
#=> ピーマンは好きですか? => いいえ
# ピーマンは好きですか? => いいえ
# ピーマンは好きですか? => はい
# トマトは好きですか? => はい
# セロリは好きですか? => いいえ
# セロリは好きですか? => はいこの章を終えて
いや、本当に長い章だった。
でも繰り返し処理はプログラミングの基本の1つだからかなり重要だよね。
そして、繰り返しとしては基本は配列。
いわゆる、基本の基本だからこれだけボリューミーなのも頷ける。
何度も何度も見ることで、よりコンパクトで可読性の高いコードを書けるようになるんだろうね。
予約システムなんかを作るときは大量のifを書いたり、範囲オブジェクトがうまく利用できずにたくさんfindやらwhereやらを使ってたけど、「これならもっとコンパクトに書けそう!」っていうアイディアがいくつも出てきた。
何かアプリを作って、そのリファクタリングを考えるときにこの本を読み返すとすごいためになりそう。
capter05 ハッシュやシンボルを理解する
ハッシュ
- 連想配列のこと。
シンボル
シンボルは任意の文字列と一対一に対応するオブジェクトです。
伊藤 淳一. プロを目指す人のためのRuby入門[改訂2版] 言語仕様からテスト駆動開発・デバッグ技法まで Software Design plus (p.449). 株式会社技術評論社. Kindle 版.
文字列の代わりに用いることもできますが、必ずしも文字列と同じ振る舞いをするわけではありません。同じ内容のシンボルはかならず同一のオブジェクトです。
:apple.class #=> Symbol
'apple'.class #=> String# シンボルは全て同じid(一意である)
:apple.object_id #=> 1143388
:apple.object_id #=> 1143388
:apple.object_id #=> 1143388
# 文字列は同じものでもidが異なるので異なるオブジェクト
'apple'.object_id #=> 70223819213380
'apple'.object_id #=> 70223819233120
'apple'.object_id #=> 70223819227780ハッシュのキーにシンボルを使う
- ぱっと見、意味不明だけど(シンボルだけど文字列みたい)、シンボルはキーにするときは書き方が変わって文字列のような見え方をする。。。
# ハッシュのキーをシンボルにする
currencies = { :japan => 'yen', :us => 'dollar', :india => 'rupee' }
# シンボルを使って値を取り出す
currencies[:us] #=> "dollar"
# 新しいキーと値の組み合わせを追加する
currencies[:italy] = 'euro'
# ----------------------------------------
# =>ではなく、"シンボル: 値"の記法でハッシュを作成する
currencies = { japan: 'yen', us: 'dollar', india: 'rupee' }
# 値を取り出すときは同じ
currencies[:us] #=> "dollar"シンボルのユースケース.01 状態管理
# タスクの状態を整数値で管理する(処理効率は良いが、可読性が悪い)
status = 2
case status
when 0 # todo
'これからやります'
when 1 # doing
'今やってます'
when 2 # done
'もう終わりました'
end
#=> "もう終わりました"# タスクの状態をシンボルで管理する(処理効率も可読性も良い)
status = :done
case status
when :todo
'これからやります'
when :doing
'今やってます'
when :done
'もう終わりました'
end
#=> "もう終わりました"キーワード引数
- メソッド側でキーワード引数を設定しておくと、呼び出し元で柔軟な対応ができるようになる。
- 普通にデフォルト値が配列だとしたら、キーワード引数は連想配列での初期値設定。
- 配列より連想配列の方がキーとバリューの関係性をイメージしやすいね。
def buy_burger(menu, drink: true, potato: true)
# 省略
end# キーワード引数を使わない場合
buy_burger('cheese', true, true)
buy_burger('fish', true, false)
# キーワード引数を使う場合
buy_burger('cheese', drink: true, potato: true)
buy_burger('fish', drink: true, potato: false)# drinkはデフォルト値のtrueを使うので指定しない
buy_burger('fish', potato: false)
# drinkもpotatoもデフォルト値のtrueを使うので指定しない
buy_burger('cheese')疑問: キーワード引数のシンボルはメソッド側ではシンボルとして呼び出せない
- :fromではなくfromで参照するのんがややこしい。
- あくまで引数は変数という位置付けみたい。
- だとしたらfrom:っていうのはしっくりこない気もするけど。。。。
def convert_length(length, from: :m, to: :m)
(length / UNITS[from] * UNITS[to]).round(2)
end# このように捉えれば理解できる
## シンボルは =>でも : でも定義できる
def convert_length(length, from => :m, to => :m)
(length / UNITS[from] * UNITS[to]).round(2)
end真偽値の型変換
def user_exists?
user = find_user
if user
true
else
false
end
end#上記と同等
def user_exists?
!!find_user
endこの章を終えて
- シンボルって他の言語でもデータの型としてあるのかな?
- ここで一気に難易度が増した気がする。
- 現段階では、「こんなものもあるんだな」程度の理解にとどめておいて、実際にコード上で目にしたときに改めて戻ってこよう。。。
- シンボルを最初から積極的に利用する気には、ちょっと慣れない。
capter06 正規表現を理解する
(おさらい)2種類のハッシュ記法
:name => 'Alice'
# もしくは
name: 'Alice'試しに使ってみる
text = <<TEXT
I love Ruby.
Python is a great language.
Java and JavaScript are different.
TEXT
text.scan(/[A-Z][A-Za-z]+/) #=> ["Ruby", "Python", "Java", "JavaScript"]エスケープ文字
伊藤 淳一. プロを目指す人のためのRuby入門[改訂2版] 言語仕様からテスト駆動開発・デバッグ技法まで Software Design plus (p.538). 株式会社技術評論社. Kindle 版.

正規表現のマッチ判定
- 正規表現のマッチ判定でよく利用される記法らしい。
# マッチした場合はマッチした文字列の開始位置が返る(つまり真)
'123-4567' =~ /\d{3}-\d{4}/ #=> 0
# マッチしない場合はnilが返る(つまり偽)
'hello' =~ /\d{3}-\d{4}/ #=> nil正規表現練習用のサイト
正規表現のキャプチャ
text = '私の誕生日は1977年7月17日です。'
m = /(\d+)年(\d+)月(\d+)日/.match(text)
# \d == 全ての半角数字(これよく使いそう)rubyでのキャプチャ
text = '私の誕生日は1977年7月17日です。'
m = /(\d+)年(\d+)月(\d+)日/.match(text)
# マッチした部分全体を取得する
m[0] #=> "1977年7月17日"
# キャプチャの1番目を取得する
m[1] #=> "1977"
# キャプチャの2番目から2個取得する
m[2, 2] #=> ["7", "17"]
# 最後のキャプチャを取得する
m[-1] #=> "17"
# Rangeを使って取得する
m[1..3] #=> ["1977", "7", "17"]正規表現マッチをそのまま条件判定に使う
text = '私の誕生日は1977年7月17日です。'
# 真偽値の判定とローカル変数への代入を同時にやってしまう
if m = /(\d+)年(\d+)月(\d+)日/.match(text)
# マッチした場合の処理(ローカル変数のmを使う)
else
# マッチしなかった場合の処理
endキャプチャに名前をつけられる
- これは結構使えそう!!
- linuxのawkにもあるのかな・・・??
text = '私の誕生日は1977年7月17日です。'
m = /(?<year>\d+)年(?<month>\d+)月(?<day>\d+)日/.match(text)
# シンボルで名前を指定してキャプチャの結果を取得する
m[:year] #=> "1977"
m[:month] #=> "7"
m[:day] #=> "17"正規表現と相性の良いstringクラスのメソッドたち
# scanメソッドは文字列に対して正規表現を利用する
'1977年7月17日 2021年12月31日'.scan(/(\d+)年(\d+)月(\d+)日/)
#=> [["1977", "7", "17"], ["2021", "12", "31"]]StringClass[正規表現]みたいに[]内に正規表現を使える
text = '郵便番号は123-4567です'
text[/\d{3}-\d{4}/] #=> "123-4567"# splitメソッドは区切り文字を設定して正規表現で配列を作る
text = '123,456-789'
# 文字列で区切り文字を指定する
text.split(',') #=> ["123", "456-789"]
# 正規表現を使ってカンマまたはハイフンを区切り文字に指定する
text.split(/,|-/) #=> ["123", "456", "789"]# gsubで文字列の置換ができる(sedコマンドみたいな)
# 第1引数に文字列を渡すと、完全一致する文字列を第2引数で置き換える
text.gsub(',', ':') #=> "123:456-789"
# 正規表現を渡すと、マッチした部分を第2引数で置き換える
text.gsub(/,|-/, ':') #=> "123:456:789"
# gsubで置換する際はブロックの方がわかりやすい
# 第2引数の代わりにブロックを使うと、バックスラッシュをどうエスケープするか迷わずに済む
# キャプチャした文字列は$1や$2で参照でき、ブロックの戻り値が置き換え後の文字列になる
text.gsub(/(\d+)年(\d+)月(\d+)日/) do
"#{$1}-#{$2}-#{$3}"
end
#=> "誕生日は1977-7-17です"正規表現の効率の良い作業の進め方
- Rubularみたいな正規表現のGUIサイトで確認しながら作業すると早い!
- 確かに、リアルタイムで確認しながら作業できるのはでかい。
正規表現で文字列の種類を判定する
- caseと正規表現の組み合わせがわかりやすい!
- これなら、入力場所を文字列にして自由に記述してもらってもバリデーションできるし、エラーメッセージも出しやすい。
text = '03-1234-5678'
case text
when /^\d{3}-\d{4}$/
puts '郵便番号です'
when /^\d{4}\/\d{1,2}\/\d{1,2}$/
puts '日付です'
when /^\d+-\d+-\d+$/
puts '電話番号です'
end
#=> 電話番号です正規表現のオプション
- i … ignorecase(大文字小文字を無視)
- m … multiline(改行文字にも.がマッチする)
- x … extended(空白文字が無視され、正規表現内部にコメントアウトできる)
この章を終えて
- 正規表現は常にマスターしたいと思いながらもなかなか手をつけ続けるのが難しい分野だったけど、今回でちょびっと定着した。
- 正規表現ってlinuxでファイル検索でもしない限りあんまり多用しない。
- これからGUI操作をどんどんCLIで置換していこう。トレーニングのために。
- PCでの定型作業を効率化するには正規表現とLinuxの組み合わせが最強だからね。
capter07 クラスの作成を理解する
この章はしっかり理解して着実に進みたい!!
改札機プログラムの実行例
# 改札機オブジェクトの作成
umeda = Gate.new(:umeda)
mikuni = Gate.new(:mikuni)
# 160円の切符を購入して梅田で乗車し、三国で降車する(NG)
ticket = Ticket.new(160)
umeda.enter(ticket)
mikuni.exit(ticket) #=> false
# 190円の切符を購入して梅田で乗車し、三国で降車する(OK)
ticket = Ticket.new(190)
umeda.enter(ticket)
mikuni.exit(ticket) #=> trueクラスを使うメリット/使わないデメリット
- データの持ち方と振る舞いをクラスごとに定義できるから便利だね!
- ハッシュだとデータの構造が崩れやすい -> クラスだとデータ構造の変化の際は一手間必要だからちょっと安心
- ハッシュだとグローバル関数になるけど、クラスならクラス単位でクラスメソッドを定義できるので、関数の管理がやりやすくなる
オブジェクトとインスタンスの違いは??
同じ意味のようです。
レシーバー
メソッドの呼び出しもとのインスタンス(オブジェクト)
Users.find(1)
# この場合はUsersがレシーバー(受取人)
# メソッドの返り値を受け取る人っていう意味だろうね。状態
オブジェクトの持つデータのこと。
# 例
User.new(name: 'alice')
# このインスタンスはAliceという状態を持っている属性
オブジェクトの持つカラムのこと。
上記でいうnameだね。
オブジェクトは共通の属性を持っていて、属性に対して状態を持っている(場合がある)と言える。
ここまで整理
- オブジェクト指向ではクラスを使う。
- クラスを使うと配列を使う時と異なりデータ管理がやりやすくなる。
- 具体的にはデータの構造と振る舞いをクラス内部に定義できる。
- クラスはインスタンス(オブジェクト)を生成する。
- オブジェクトは全て共通の属性を持っていて、属性に対して状態を持つ場合がある。
- クラスがオブジェクトを管理し、オブジェクトが属性や状態を管理することで、配列では難しいデータの複雑な管理ができるようになる。
- これがオブジェクト指向の基本。
クラスの基本
# 必ず大文字・キャメルケース
class クラス名
end# インスタンスの作成
User.new# コンスタンスメソッド
## インスタンス生成時の初期化メソッド
## 引数を設定するとインスタンス化で引数が必須になる
class User(name, age)
def initialize
end
end# インスタンスメソッド
## クラス内部で定義された独自のメソッド
class User
def hello
end
end
user = User.new
user.hello# インスタンスメソッド
## インスタンスメソッドはクラスの外部からは参照できない
class User
def initialize(name)
# インスタンス作成時に渡された名前をインスタンス変数に保存する
@name = name
end
def hello
# インスタンス変数に保存されている名前を表示する
"Hello, I am #{@name}."
end
end
user = User.new('Alice')
user.hello #=> "Hello, I am Alice."アクセサメソッド
- ゲッターメソッドやセッターメソッドを1行で完結させてしませる。
- 普段Railsでやってれば意識しないけど、`user.name`でnameカラムを取得したり変更したりできるのはRails側でその処理を自動化してくれてるからでは・・・?
# アクセサメソッドがない場合
## それぞれ、read, writeするためのメソッドが必要になる。
class User
def initialize(name)
@name = name
end
# @nameを外部から参照するためのメソッド
def name
@name
end
# @nameを外部から変更するためのメソッド
def name=(value)
@name = value
end
end
user = User.new('Alice')
# 変数に代入しているように見えるが、実際はname=メソッドを呼びだしている
user.name = 'Bob'
user.name #=> "Bob"# アクセサメソッドを使う場合
## 1行でゲッタ・セッタメソッドを定義できる
class User
# @nameを読み書きするメソッドが自動的に定義される
attr_accessor :name
def initialize(name)
@name = name
end
# nameメソッドやname=メソッドを明示的に定義する必要がない
end
user = User.new('Alice')
# @nameを変更する
user.name = 'Bob'
# @nameを参照する
user.name #=> "Bob"同じクラスを複数定義するとどうなる?
- 既存のクラスに上書きされる。
- 追加のクラスでメソッドを定義すると、既存のメソッドに追加で実装される。
- 置き換えではなく、上書きであることに注意。
クラスメソッドとインスタンスメソッド
- インスタンスメソッド
- 「個別のインスタンスが持つ」属性や状態を利用した処理を実装していく。
- クラスオブジェクトから実行可能。
- User.all(クラスオブジェクト.クラスメソッド)
- 「self.メソッド名」とすればクラスメソッドに。
- クラスメソッド
- 個別インスタンスの情報を特段利用しないような処理を書く。
- インスタンスから実行可能。
- user.name(インスタンス.インスタンスメソッド)
- self.をつけずに定義すればインスタンスメソッドに。
lass User
def initialize(name)
@name = name
end
# self.を付けるとクラスメソッドになる
def self.create_users(names)
# mapメソッドを忘れた人は「4.4.1 map/collect」の項を参照
names.map do |name|
User.new(name)
end
end
# これはインスタンスメソッド
def hello
"Hello, I am #{@name}."
end
endnames = ['Alice', 'Bob', 'Carol']
# クラスメソッドの呼び出し
users = User.create_users(names)
users.each do |user|
# インスタンスメソッドの呼び出し
puts user.hello
end
#=> Hello, I am Alice.
# Hello, I am Bob.
# Hello, I am Carol.実は2種類あるクラスメソッドの定義方法
- どちらでも定義できる。
def self.hello
enddef User::hello
end今回作成するプログラムの処理手順
# 改札機オブジェクトの作成
## Gateクラスを使ってるね。
umeda = Gate.new(:umeda)
mikuni = Gate.new(:mikuni)
# 160円の切符を購入して梅田で乗車し、三国で降車する(NG)
## Ticketクラスを使ってるね。
ticket = Ticket.new(160)
## Gateクラスのインスタンスメソッドの引数としてTicketのインスタンスを渡してる。
## ここで2つのクラスを跨いで処理を実装してる。
## 処理の結果は単純にtrue or falseを返すだけ
umeda.enter(ticket)
mikuni.exit(ticket) #=> false
# 190円の切符を購入して梅田で乗車し、三国で降車する(OK)
ticket = Ticket.new(190)
umeda.enter(ticket)
mikuni.exit(ticket) #=> true実装のイメージ
・Gateクラスのenterメソッドは、引数として渡された切符(Ticket)に自分の駅名を保存する。
・Ticketクラスにstampというメソッドを用意する。このメソッドに駅名を渡すとその駅名がTicketクラスのインスタンスに保存される。
・乗車駅を取得する場合はTicketクラスのstamped_atメソッドを使う。
・Gateクラスのexitメソッドは、引数として渡された切符(Ticket)から運賃(fare)と乗車駅を取得する。
・exitメソッドではさらに乗車駅と自分の駅名から運賃を割り出す。運賃が足りていればtrueを、そうでなければfalseを返す。
# 乗車駅と自分の駅名から運賃を割り出す
ここの実装のイメージがわかない・・・。
.
.
.
# テキストでは、駅名と運賃の配列をそれぞれ用意して、indesの数値で区間を計算してる。
# なるほどなあ・・・・ってなったわ。
# 区間を数値化するために配列を使うっていうのは他でも使えそうな発想。プログラムのシーケンス図の書き方や読み方がわからない
ここまでの実装の内容でのポイント
- 登場人物
- :umedaと:jusoっていう2つのGateインスタンス
- ticketという160円の初期値を持ったTicketインスタンス
- ticketを2つの駅に渡すことで金額の判定をしてる
- こう見ると、プログラムは現実世界の考え方を参考にすると作りやすい。
- 最初はGateの中に全て実装できるじゃん。と思ってたし、それでもできるんだけど、汎用性の観点からTicketクラスにしておくと良いだろうね。
- 現実世界でも、駅とチケットは別々のモノ(オブジェクト)だから、プログラムの世界でも別々のクラスとして定義してるって言われるとわかりやすい。
- 駅とチケットを1つのクラスとして定義するなら、Stationみたいになるのかな。
- Stationクラスが:stop, :ticketっていう2つの属性を持ってるみたいな。
- そういう作り方もできるんだろうけど、処理がより複雑になっていきそう。
- ミスタードーナツでドーナツを買うプログラムだったら?
- 登場人物
- Storeクラス … 各店舗
- donut … メニューにあるドーナツ
- customer … お客さん
- payment … 1つ1つのお会計
- これでいい感じにオブジェクト指向でプログラムを作れるのか・・・?
- これまでクラスとかあまり意識せずに書いてきたけど、意識して使えれば、かなり工数を省略してプログラムを書いていけるんじゃ・・・。
- 登場人物
# test/gate_test.rb
def test_gate
## 乗り降りする駅をそれぞれ定義してる
## この世界では今の所2つの駅があることになっている
umeda = Gate.new(:umeda)
juso = Gate.new(:juso)
# 160円の切符を購入する
## 乗り降りする駅を保存しておくチケットのインスタンスを発行してる
## 現実の世界でいう切符のような役割を担ってくれる
## ここでは160円の切符を発行してる意味になる
ticket = Ticket.new(160)
# 梅田で入場し、十三で出場する
## 梅田駅というインスタンスに対して160円の切符を渡してる
## enterメソッドは160円の切符に梅田駅のスタンプを押す
umeda.enter(ticket)
# 期待する結果:出場できる。
## exitはjuso駅というインスタンスで160円の切符が使えるかのメソッド
## exit?の方が良さそうだけど。。。
assert juso.exit(ticket)
endselfキーワードがややこしい
- selfは呼び出し箇所によってクラスだったりインスタンスだったりする。
- クラスメソッド内 … クラス
- インスタンスメソッド内 … インスタンス
class Foo
# 注:このputsはクラス定義の読み込み時に呼び出される
puts "クラス構文の直下のself: #{self}"
def self.bar
puts "クラスメソッド内のself: #{self}"
end
def baz
puts "インスタンスメソッド内のself: #{self}"
end
end
#=> クラス構文の直下のself: Foo
Foo.bar #=> クラスメソッド内のself: Foo
foo = Foo.new
foo.baz #=> インスタンスメソッド内のself: #<Foo:0x000000012da3e2f0>インスタンスメソッド内でクラスメソッドを呼び出す
- どちらの記述でも同じ。
# クラス名.メソッドの形式でクラスメソッドを呼び出す
Product.format_price(price)
# self.class.メソッドの形式でクラスメソッドを呼び出す
self.class.format_price(price)ここまでの情報を整理
- ポイント
- オブジェクト指向は現実の世界のモノに例えると、途端にわかりやすくなる。
- 駅・切符を使った料金計算とかね。
- オブジェクト指向は現実の世界のモノに例えると、途端にわかりやすくなる。
- キーワード
- クラス
- インスタンス
- クラスメソッド
- インスタンスメソッド
- アクセサメソッド
# 特に勉強になったコード
umeda.enter(ticket)
## umedaというgateインスタンスに160円という状態を持つticketインスタンスを渡してる
## enterメソッド内部ではticketに:umedaというスタンプを押している
## この1行でこのチケットは梅田駅から160円のチケットで入場したと表現してる
## 2つのクラスのインスタンスをうまく組み合わせて駅の乗り降りを表現してるクラスを継承する判断基準「is-aの関係」
- クラスを継承するのが適切かどうか。
- 「DVD is a Product」 DVDは商品の一種である。
- これに違和感がなければok。
- サブクラスはスーパークラスの性質を特化したもの。
- スーパークラスはサブクラスを汎化したもの。
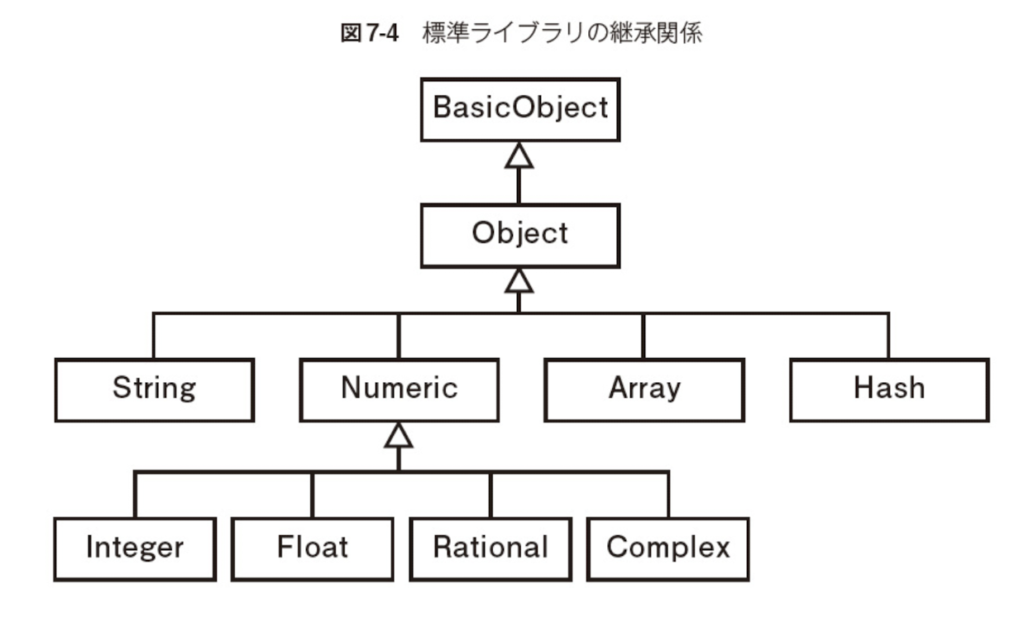
標準ライブラリの継承関係
クラスを継承してみる
class DVD < Product
end属性の定義と継承
- スーパークラスで定義した属性はそのままサブクラスでも定義不要で使える
- サブクラスでは追加で属性を定義できる
class DVD < Product
# nameとpriceはスーパークラスでattr_readerが設定されているので定義不要
attr_reader :running_time
def initialize(name, price, running_time)
# スーパークラスにも存在している属性
@name = name
@price = price
# DVDクラス独自の属性
@running_time = running_time
end
end
dvd = DVD.new('A great movie', 1000, 120)
dvd.name #=> "A great movie"
dvd.price #=> 1000
dvd.running_time #=> 120superメソッド
- スーパークラスの「同名メソッド」を呼び出せる
class DVD < Product
attr_reader :running_time
def initialize(name, price, running_time)
# スーパークラスのinitializeメソッドを呼び出す
super(name, price)
@running_time = running_time
end
end# 下記のようなインスタンス変数の定義が不要になり、superクラスの同名メソッド(initizlideメソッド)を引き継げる
@name = name
@price = priceメソッドのオーバーライド
- 単純に、スーパークラスと同じ名前のメソッドを定義するだけ。
- 差分のみコーディングすることで効率的に処理を拡張していける。
Productクラスでto_sメソッドをオーバーライドして見やすく出力を制御。
class Product
# 省略
def to_s
"name: #{name}, price: #{price}"
end
endDVDクラスでさらにto_sメソッドをオーバーライドして、使いやすくする。
class DVD < Product
# 省略
def to_s
"name: #{name}, price: #{price}, running_time: #{running_time}"
end
end記述の前半はスーパークラスと同じなので、superメソッドで返り値をそのまま使う。
後半はDVDクラス独自のものになる。
class DVD < Product
# 省略
def to_s
# superでスーパークラスのto_sメソッドを呼び出す
"#{super}, running_time: #{running_time}"
end
endこれで、それぞれのクラスで同じメソッドでも返り値が異なる。
product = Product.new('A', 100)
product.to_s
dvd = DVD.new('A', 100, 10)
dvd.to_sクラス内の定数を外部から参照できる
class Product
DEFAULT_PRICE = 0
endProduct::DEFAULT_PRICEクラスをfreezeして変更不可に
- freezeメソッドを使うとクラスの内容を変更できなくなる。
- rubyの定数は変更できる変数なのでfreezeしないと普通に変更できてしまう。
Product.freeze# 定数を本当の定数として利用するにはfreezeを定数に利用する
# rubyは変数の代入も式なので値を返すからチェーンメソッドできる
(DEFAULT_PRICE = 0).freeze
再登場、便利なcaseと正規表現マッチング
text = '03-1234-5678'
case text
when /^\d{3}-\d{4}$/
puts '郵便番号です'
when /^\d{4}\/\d{1,2}\/\d{1,2}$/
puts '日付です'
when /^\d+-\d+-\d+$/
puts '電話番号です'
end
#=> 電話番号ですオブジェクトに挙動を与える特異メソッド
alice = 'I am Alice.'
bob = 'I am Bob.'
# aliceのオブジェクトにだけ、shuffleメソッドを定義する
def alice.shuffle
chars.shuffle.join
endダックタイピング
- 抽象具象のクラスの境目を気にせずプログラムをかける。
- 静的型付け言語ではコンパイルの際に型チェックをして、確実にオブジェクトがメソッド実行できることを保証する。
- Rubyのような動的型付言語は実行時にチェックをするので実行するまでわからない。
メソッドの有無を調べる
s = 'Alice'
# stringクラスはsplitメソッドを持つ。
s.respond_to?(:split)この章を終えて
- クラスを使いこなせれば、かなり効率的にプログラムをかける。
- 保守性・拡張性が高く、柔軟なコード。
- 特にエンハンス作業になるとこの理解がないとついていけないだろうね。
capter08 モジュールを理解する
モジュールの用途
- 継承を使わずにクラスにインスタンスメソッドを追加する、もしくは上書きする(ミックスイン)。
- 複数のクラスに対して共通の特異メソッド(クラスメソッド)を追加する。
- クラス名や定数名の衝突を防ぐために名前空間を作る。
- 関数的メソッドを定義する。
- シングルトンオブジェクトのように扱って設定値などを保持する。
クラスとの違い
- モジュールからインスタンスを作成することはできない。
- ほかのモジュールやクラスを継承することはできない。
# モジュールのインスタンスは作成できない
greeter = Greetable.new #=> undefined method `new' for Greetable:Module (NoMethodError)
# 他のモジュールを継承して新しいモジュールを作ることはできない
module AwesomeGreetable < Greetable
end
#=> syntax error, unexpected '<' (SyntaxError)moduleユースケース. 継承を使わずに共通処理を実装したい
以下の処理はミックスインと呼ばれるらしい(クラスにモジュールをincludeすること)
- is_aの関係性にない複数のクラス間で共通処理を実装する。
- 抽象クラスを作らずにmoduleで対応できる。
- ただ、インスタンスを生成できないのでメソッドのみの記述になる?
- クラスに定義すると「単一継承」なので面倒なことになる。
モジュールのメソッドはprivateにすべき?
module Loggable
# logメソッドはprivateメソッドにする
private
def log(text)
puts "[LOG] #{text}"
end
endclass Product
include Loggable
# 省略
endproduct = Product.new
# logメソッドはprivateメソッドなので外部から呼び出せない
product.log 'public?'
#=> private method `log' called for #<Product:0x000000013d37a210 ...> (NoMethodError)- privateにすることでインスタンスから呼び出すことを避けられる。
- 今回の例だと、クラス内の処理でログを出すことは許可できるけど、インスタンスからログを出すことは許可しない。とかね。
- privateメソッドにすることでclass ~ endの外で呼べなくなる。
- いまいちやっぱりピンとこないけど、セキュリティ的な観点から重要なんだろう。
- あとは、コードの保守の観点から、どこからでも呼べるようにしたくないとか??
- 色んな場所で使われるとそれだけメンテナンスが面倒になるからね。
moduleユースケース. クラスの特異メソッドにしちゃえ
class Product
# Loggableモジュールのメソッドを特異メソッド(クラスメソッド)としてミックスインする
extend Loggable
def self.create_products(names)
# logメソッドをクラスメソッド内で呼び出す
#(つまりlogメソッド自体もクラスメソッドになっている)
log 'create_products is called.'
# 他の実装は省略
end
end# クラスメソッド経由でlogメソッドが呼び出される
Product.create_products([]) #=> [LOG] create_products is called.
# Productクラスのクラスメソッドとして直接呼び出すことも可能
Product.log('Hello.') #=> [LOG] Hello.- extendすることでクラスの内部メソッドとして定義できる。
- だから、インスタンスでも利用できるようになる。
- module内のメソッドを、User.allとかuser.findみたいな使い方ができるわけだね。
- 全てのクラスで共通するメソッドはmoduleに定義して、extendすることで、関連性のない複数のクラス共通のクラスメソッドが誕生する。。
- superクラスで定義しても良いだろうけど、サブクラス同士に関連性がないならきついな。
- superクラスを継承したクラスの全てでは必要ないけど、みたいな時にextendは使えそう。
面白いコード
# 31〜35をずっとループする処理
# 「余り」を使ったこんな処理があるんだなあ・・・・。
color = 31 + 25 % 6- これを使わないなら、、、文字の個数を6で割って・・・・とかやって何行にもなる。
- これはすごい。
クラスメソッドの有無を確認
# モジュールの有無を確認
Product.include?(String)
# includeしたモジュールを全て表示
Rainbowable.indluded_method
# 先祖まで遡ってincludeしたモジュールを全て表示
Rainbowable.ancestors